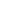


Thanks for that, Morganni. Looks like exactly the kind of thing I was looking for. I'll decide later whether to integrate it, or just leave it as an attachment.
Okay, I'm essentially done with my crawl of the wiki. I was intentionally vague about what I was doing, because I didn't know exactly who was watching the thread. Now that that's over, I can give you a better idea of what I downloaded. I have 180,080 pages in wiki code of 188,536 that the article count lists. Some of the disparity is in namespaces like Sekrit/ which is completely locked down, but the 7518 of the missing articles are from the Main namespace. Main/ does not have an listing page, so I just had to get that by crawling the wiki. Any page which was intentionally blanked would be indistinguishable from from a non-page, so that may be part of the missing data. The remainder is likely zero wick pages that don't attract much attention.
I ended up just crawling the wiki source code only, because this allowed me to both minimize the bandwidth used while saving the data in its most portable, compressed form. I did have to write a lightweight parser to find the links, which wasn't as perfect as I would have liked. It ended up picking up line noise gibberish -- probably parts of external links -- that managed to fit the syntax for WikiWords. I probably could have prevented that, but it took me four hours from inspiration to operational code, and it did the job well for that amount of time. If enough bad links built up, I just asked the TV Tropes parser to preview a page, and tell me which links are redlinks.
I seeded with the page HGamePOVCharacter, which I just happened to have sitting around because it looked like TRS was going to delete it. I probably should have started with IndexIndex, but it eventually got there. To finish off anything I may have lost, I looked through every wick to every single one of the TropesOfLegend. The upshot of crawling the source code is it avoids the messages about "We do not want a page on this topic" -- those display just fine in source code mode. It also keeps all of the redirects as separate pages, which are very useful for finding stuff.
This was quite a fun, complicated project. It's more data than I've dealt with since the last time I ran a weather model in grad school. The final size is 1.95GB on disk, though it should compress nicely. Alright, time to give the router a rest.
-- ∇×V
Okay, I'm essentially done with my crawl of the wiki. I was intentionally vague about what I was doing, because I didn't know exactly who was watching the thread. Now that that's over, I can give you a better idea of what I downloaded. I have 180,080 pages in wiki code of 188,536 that the article count lists. Some of the disparity is in namespaces like Sekrit/ which is completely locked down, but the 7518 of the missing articles are from the Main namespace. Main/ does not have an listing page, so I just had to get that by crawling the wiki. Any page which was intentionally blanked would be indistinguishable from from a non-page, so that may be part of the missing data. The remainder is likely zero wick pages that don't attract much attention.
I ended up just crawling the wiki source code only, because this allowed me to both minimize the bandwidth used while saving the data in its most portable, compressed form. I did have to write a lightweight parser to find the links, which wasn't as perfect as I would have liked. It ended up picking up line noise gibberish -- probably parts of external links -- that managed to fit the syntax for WikiWords. I probably could have prevented that, but it took me four hours from inspiration to operational code, and it did the job well for that amount of time. If enough bad links built up, I just asked the TV Tropes parser to preview a page, and tell me which links are redlinks.
I seeded with the page HGamePOVCharacter, which I just happened to have sitting around because it looked like TRS was going to delete it. I probably should have started with IndexIndex, but it eventually got there. To finish off anything I may have lost, I looked through every wick to every single one of the TropesOfLegend. The upshot of crawling the source code is it avoids the messages about "We do not want a page on this topic" -- those display just fine in source code mode. It also keeps all of the redirects as separate pages, which are very useful for finding stuff.
This was quite a fun, complicated project. It's more data than I've dealt with since the last time I ran a weather model in grad school. The final size is 1.95GB on disk, though it should compress nicely. Alright, time to give the router a rest.
-- ∇×V